Vital A.I.
A.I. Agent Ecosystem
The Vital Agent Ecosystem provides a collection of software components, knowledge models, and interfaces that together provide an A.I. Agent development, deployment, and management platform. (more)
Chat.ai Agent App
Using the Vital AI Agent Ecosystem, Vital has launched Chat.ai as an end-user application to utilize A.I. Agents and as a developer platform to deploy Agents. Chat.ai
Knowledge Graph
Knowledge Graphs are a critical component of A.I. applications. Vital provides tools to help build and manage Knowledge Graphs and use them within A.I. Applications and Agents. (more)
Consulting
Vital provides consulting services from short sessions supporting your A.I. strategy to extensive implementations of A.I. Applications. Please contact us to explore ways to work together! (more)
Vital A.I. Agent Ecosystem
The A.I. Agent Ecosystem is a set of software components and knowledge models that allow developing, deploying, and managing A.I. Agents. The Ecosystem is available in an open-source model with commercial support available from Vital. As an ecosystem, A.I. Agents interact autonomously not only with people, but also other agents. The Ecosystem includes features necessary for an Enterprise deployment of an Agent Ecosystem including horizontal scalability, data goverance, and isolation/containerization of Agent implementations.
More information is available here:

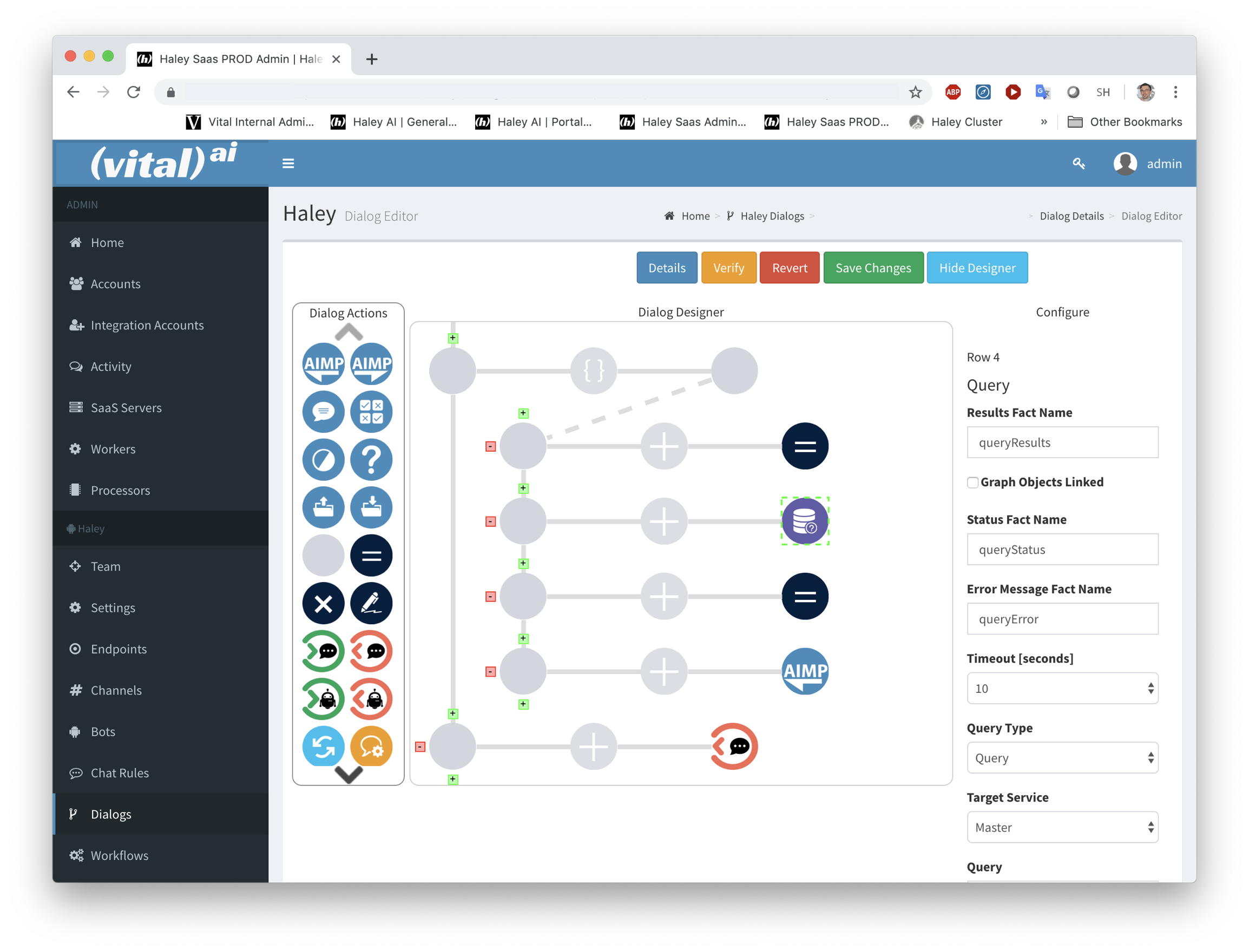
Agent Ecosystem Managed Solution
The Agent Ecosystem is available as a managed solution. This creates a private instance of the Ecosystem for your organization, which may be further customized and integrated with your other IT infrastructure. The deployment can be placed in a geographic location of your choosing such as United States/North America, Europe, or Asia as required by your organization. Pricing of the Managed Solution is usage based.
More information is available here:
Vital A.I. Agent Development
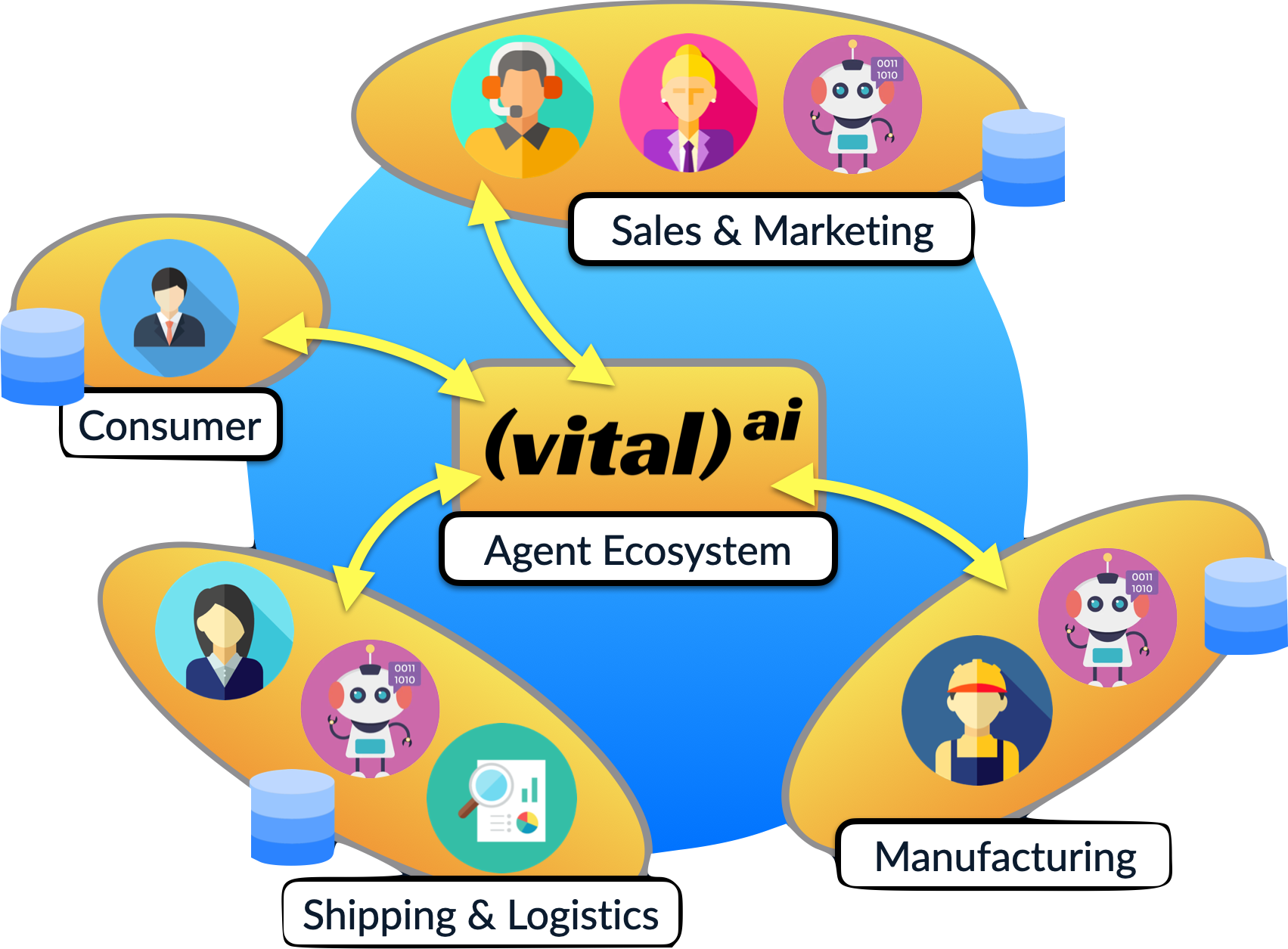
Developing an A.I. Agent can be a complex process as it involves the intersection of Business Leaders and Domain Experts that determine the desired behavior of the Agent, Infrastructure and DevOps Engineers to scale the required infrastructure, Software Developers to implement the user experience and integrate the software components, and A.I. Experts to implement and tune the desired behavior and enforce the necessary guardrails to align the A.I. with the goals of the effort. Vital can help with these efforts to augment your team and provide the necessary expertise to make your Agent implementation a success, as well as continue to revise and improve the Agent going forward.
Knowledge Graph
Knowledge Graphs are a critical component of A.I. Applications. Knowledge Graphs encode knowledge in a structured way that can be utilized across all elements of the A.I. Application, including with a Large Language Model (LLM). This allows the knowledge encoded within a Large Language Model to be augmented with additional knowledge that the Agent can use to achieve its goal. Vital provides tools to help build and manage Knowledge Graphs such as VitalSigns. VitalSigns compiles Knowledge Models (Ontologies) into software artifacts allowing Knowledge Models to be utilized directly in software, such as when querying a Graph or Vector Database to find relevant knowledge to use with the LLM.
Knowledge Graphs are in the form of graphs - nodes linked by edges, or if you prefer, dots connected by lines. The nodes represent entities or things and the edges represent relationships between those things.
Elements of a Knowledge Graph are easy to understand - a node representing "John", a person, may be connected to a node representing "Pizza", a food, with a relationship representing "likes". By looking at the graph, you can understand "John likes Pizza", and so can the A.I. By representing knowledge in this way, all parts of the application - user interface, database, the A.I. - and the developers creating the application - can all agree on what the knowledge used in the application means.
Haley A.I. Assistant
Haley is an intelligent agent assistant. Haley consists of models and behaviors combined together into an Agent that is deployed on the Agent Ecosystem. Haley is integrated with a number of resources such as email, text messaging, weather information, voice understanding, and voice generation. Haley can be the basis of an Agent Assistant deployed for your organization in the Ecosystem, or accessed within Chat.ai.
More information about Haley is available here:

Vital A.I. Consulting Services
Vital AI provides consulting services ranging from A.I. informational and strategy sessions to complete Agent implementations utilizing the Agent Ecosystem. Please reach out to discuss your needs. You may use the "Book Appointment" link below to book a short consulting session, or contact us to discuss a longer engagement.

A.I. and Machine Learning
A.I. comes in many forms and flavors, and an A.I. Agent can combine many forms together. Depending on the requirements of an Agent, the component models of the Agent are selected.
These can include:
- Generative Models for Language or Images from commercial and open source providers such as GPT-4 (OpenAI), DALL-E 3 (OpenAI), Claude (Anthropic), Llama2 (Meta), or Gemini (Google). Generative Models are also available for voice, video, and other outputs.
- Fine-tuning models, such as Llama2, to adjust their behavior.
- Creating prompts for a generative model ("prompt engineering") to get the desired outputs from the model.
- Tuning queries to a Knowledge Graph or other database or document search as part of "Retrieval Augmented Generation" (or "RAG") process. In RAG, a query produces relevant knowledge that is then used by a Generative Model to produce a final result. This process can be repeated over multiple steps with the generative model producing a request for knowledge, a query done to retrieve that knowledge, and then the generative model producing a new request based on the new knowledge or generating a completed result.
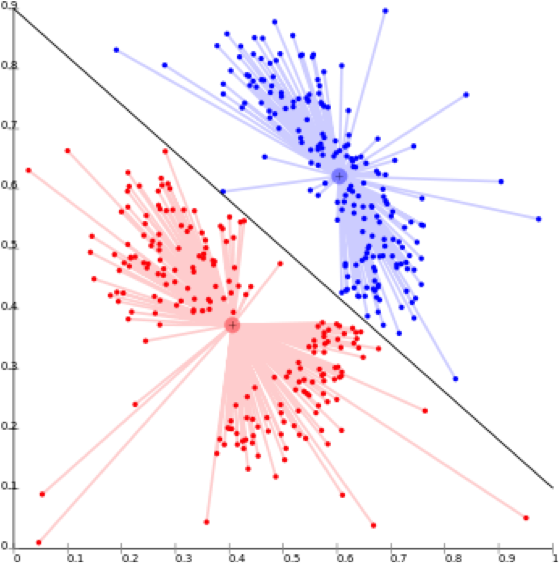
- Predictive models trained with data to predict likelihood or numerical outcomes.
- Recommendation models trained with data to make recommendations from a set of available options.
- Reasoning models trained to produce structured output such as a plan composed of steps to achive a goal, or a itinerary produced by a routing model.
Vital can help create, deploy, and maintain these different forms of A.I. and integrate them into your Agents via our consulting services.
VitalSigns and the Vital Development Kit (VDK)
VitalSigns and prior versions of the Vital Development Kit (VDK) from 2023 and earlier are now part of the A.I. Agent Ecosystem and available in an open-source license. This includes components such as VitalService which provides interfaces to databases including SQL, Graph (SPARQL), and Vector databases.
